Primeros pasos con Bonita BPM
Community 6.2.6
Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Instalación
- 4. Creación de un flujo
1. Introducción:
Vamos a instalar Bonita y dar
unos pequeños pasos con este gestor de BPM.
2. Entorno.
El tutorial ha sido escrito
usando el siguiente entorno:
▪
Hardware: Portátil MacBook Pro 13′
(2.7 GHz Intel Core i7, 8GB DDR3).
▪
Sistema Operativo: Mac OS
Mavericks 10.9.2
▪
Java 7 (instalar con la versión mas moderna)
▪
Bonita BMP Community 6.2.6
3. Instalación.
Antes de empezar os recomiendo
ejecutar desde la línea de comando, la app Terminal, el comando: java
-version.Si no tienes instalado el interprete de Java (JRE) te arrancará el
proceso.
Vamos a bonitasoft y descargamos la última
versión.
Ejecutamos la app descargada.
Recordad hacerlo pulsando el botón derecho para que os aparezca la opción de
instalar (esto bajo responsabilidad de cada uno ya que es software descargado
desde Internet).
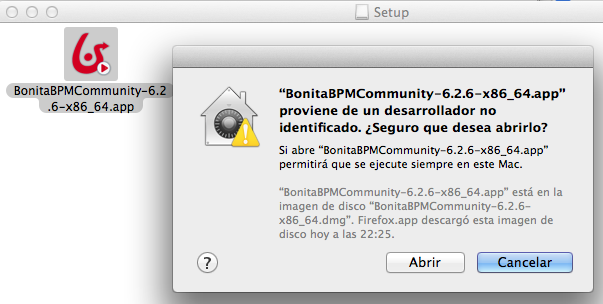
Es posible que no os funcione
porque no encuentre el JDK. Para ello debemos ir al site de Oracle y bajarnos
la última versión disponible para Mac.
Yo lo instalo la versión de
bonita BPM en castellano.
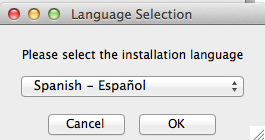
El wizard es muy intuitivo.

Elegimos el directorio de
instalación.
Seguimos instalando.
Después de un rato seguimos…Como
no quiero recuperar de un entorno anterior podremos arrancar ya Bonita BPM.
4. Creación de un flujo.
Antes de empezar, es conveniente
tener claro los roles, tareas y usuarios del proceso que queremos modelar. Voy
a empezar a modelar un proceso BPM de contratación de personal y para
proporcionar servicios de headhunting. Una herramienta BPM puede proporcionar
un sistema sencillo para integrar en un site un interfaz web en el que
participen distintas personas.
El entorno tiene un aspecto
impecable y he de decir que me ha dado muy pocos problemas. Solo, de vez en
cuando, algún problema de perder ventanas por precipitare y pedirle que haga
otra cosa cuando todavía no ha terminado la primera.
Vamos a crear un flujo básico y
conectarlo a una base de datos para ir persistiendo los datos del proceso de
contratación y selección en una base de datos. Esto lo vamos a hacer así por
comodidad pero no creo que sea el modo más adecuado.
Normalmente un motor BPM tiene
que ser la ayuda para realizar procesos en una organización. Si se convierte en
el centro del sistema tendremos un problema de tener una dependencia demasiado
grande a un único elemento arquitectónico. Un flujo BPM nos tiene que ayudar a
organizar las tareas de una parte de un proceso o del proceso completo pero la
organización tiene que tener en control del estado y de los datos en entidades
externas.
En las grandes organizaciones se
mezclan habitualmente procesos online y batch. Gran parte de esos procesos
batch pueden estar ya construidos, incluso en tecnología clásicas como Natural,
Cobol, RPG o procedimientos almacenados por lo que es importante valorar como
se van a integrar esos dos mundos.
Usando un flujo y motor BPM,
tenemos varios modos de hacerlo, cada uno mejor que el anterior:
▪
Los datos pueden guardarse en
variables transitorias almacenadas en el proceso BPM mientras está activo en el
motor, cosa que crea mucha dependencia con él.
▪
El flujo BPM puede guardar datos
directamente en una base de datos, con Scripts o mapeados visuales,
(dependiendo de las capacidades de la herramienta) para que estén muchos datos
en el proceso y los deseados en un modelo de datos concretos en una base de datos
tradicional. Cosa que va a acoplar mucho el flujo y la base de datos. Más aun
considerando que muchas organizaciones están deseando cambiar los modelos de
datos obsoletos.
▪
El flujo BPM puede informar a
servicios web (directamente o orquestados a través de un ESB) que es el que se
encargue de almacenar los datos. Hay más capas por medio pero la
responsabilidad del BPM queda más acotada al flujo visual y menos acoplado a la
persistencia.
Si el proceso BPM informa al
sistema global de la organización, a través de una capa de servicios, sobre los
cambios importantes en el proceso (recordad un patrón de diseño llamado
Memento) estaremos haciendo un uso muy equilibrado de las tecnologías (siempre
esto valorado en un contexto).
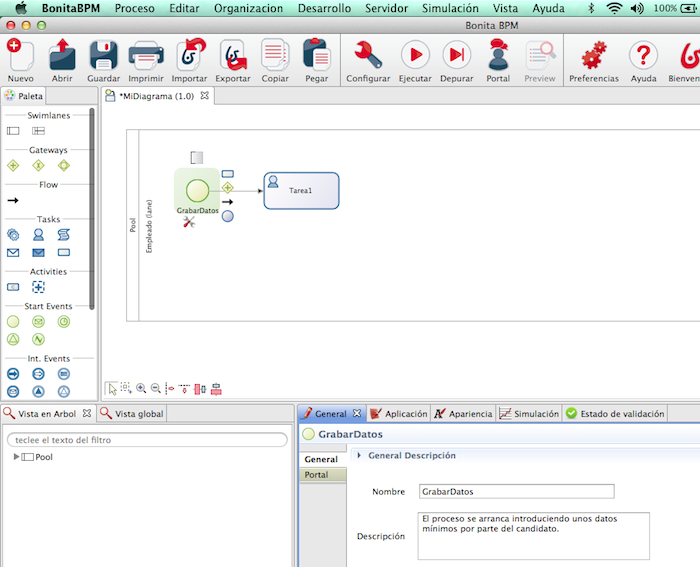
Un proceso tiene un pool o calle,
que tiene un actor por defecto. Con un círculo se representa el inicio del
proceso. Se suele iniciar el proceso desde un Api externo o desde un site
cualesquiera integrándose con la herramienta BPM.
Bonita tiene su propio portal
y podemos arrancar los procesos directamente.
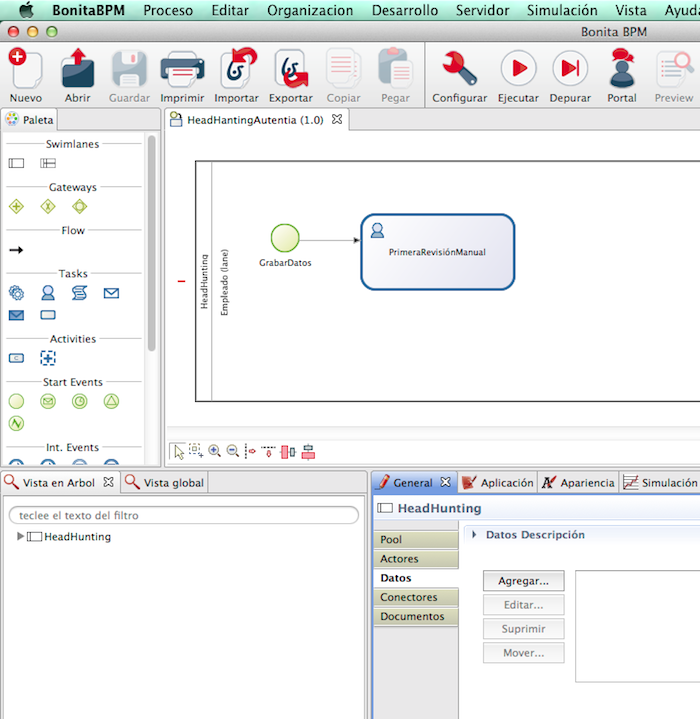
Marcando la calle principal vamos
añadir atributos necesarios en el proceso.
Estos atributos estarán disponibles
en cualquier tareas y serán persistimos automáticamente por el propio motor en
las tablas internas.
Recordad que cuando estás en desarrollo el sistema está
configurado por defecto para borrar los datos temporales. Por tanto, cada vez
que se re-arranca el servidor perdemos los datos antiguos (es fácil cambiarlo).
Añadimos todo el conjunto de
datos que tengamos pensado utilizar en el ciclo completo. En las tareas podemos
declarar variables locales necesarias para operaciones o control de flujo.
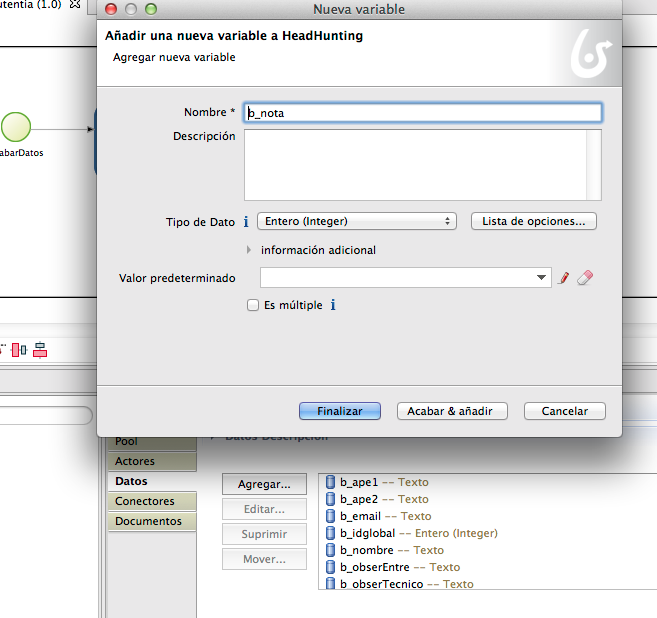
Al ejecutar el proceso vemos que
se crea un formulario paginado en base a los campos globales al proceso creado.
No vamos a prestar mucha atención a estas primeras pantallas porque como
comentaba lo lógico es arrancarlo desde otro sitio y con solamente un pequeño
conjunto de datos de todos los que aparecen.
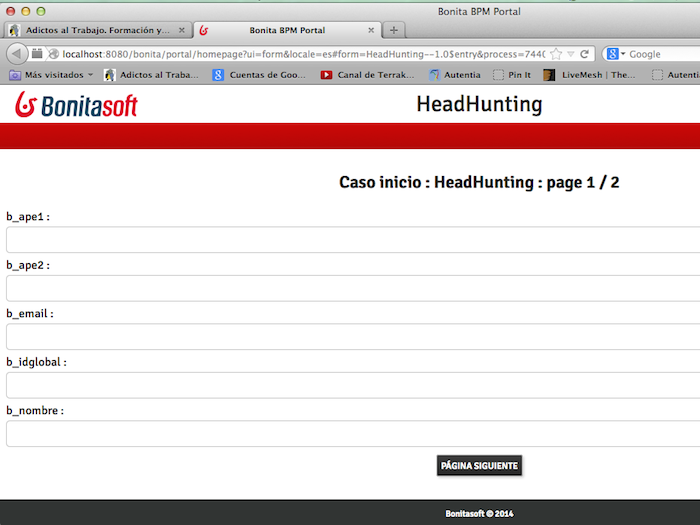
Como está todo el proceso esta en
la misma calle, al completar los datos iniciales podemos ver que aparece un
link para continuar con la tarea. esto es muy útil en desarrollo y depuración
porque sino nos tendríamos que logar con otro usuario para acceder a la tarea.
Por tanto, parece buena idea gestionar los usuarios (y otras calles en el
diagrama al final) y no al principio.
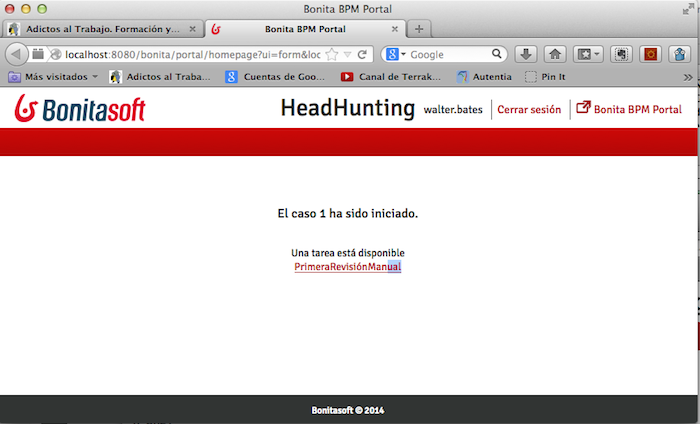
Las herramientas BPM tienen como
núcleo central una bandeja de tareas donde cada usuario dispone de un conjunto
de labores potencialmente a iniciar. Cuando un usuario elige una tarea se la
asigna (y ya no queda disponible para los demás). Al pinchar sobre ella dispone
de un formulario donde completar la tarea.
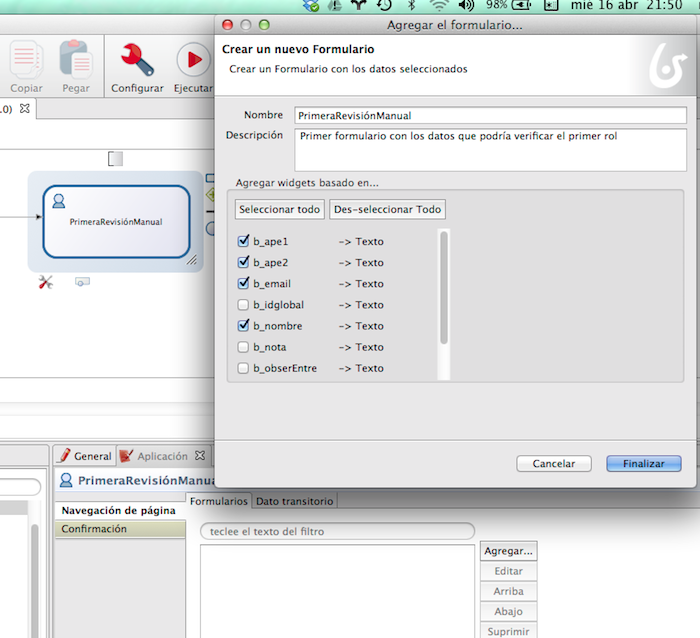
El formulario puede ser por
defecto, generado dinámicamente a partir del los campos declarados, o puede
personalizarse. Vamos a cambiar el formulario:
Pinchamos en la tarea y en la
sección aplicación. Elegimos los campos involucrados.
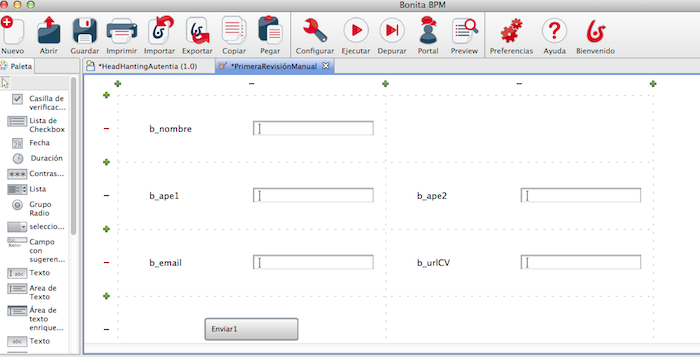
Jugamos con el formulario
recolocando los datos como nos interesa.
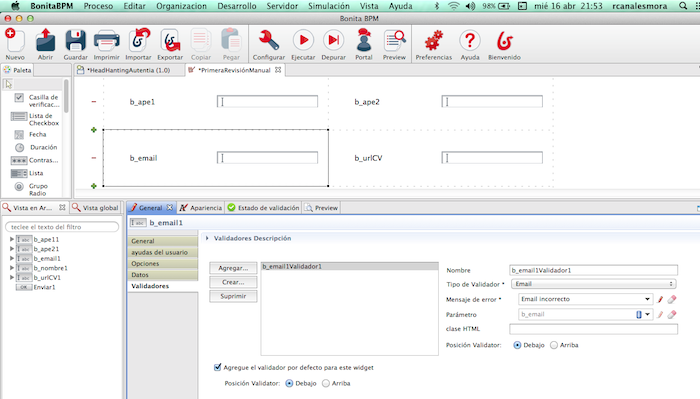
Añadimos incluso una validación
estándar proporcionada por Bonita. En este caso para el email.
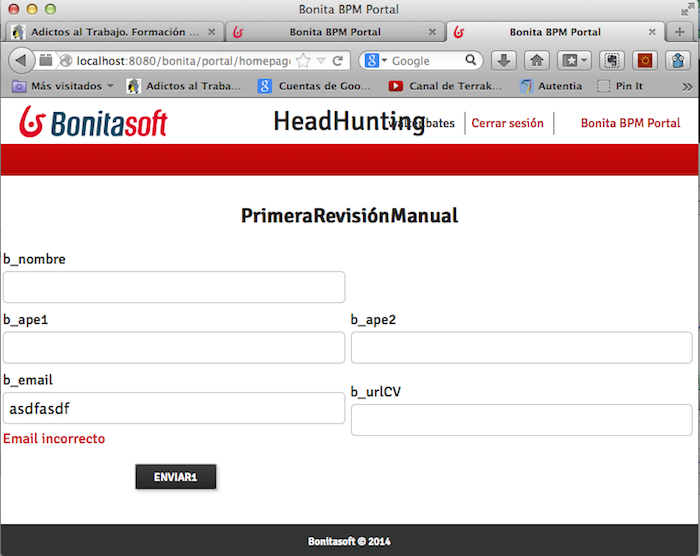
Podemos pre-visualizar los
formularios o comprobar su funcionamiento en el flujo básico. Vemos si funciona
rearrancando el proceso.
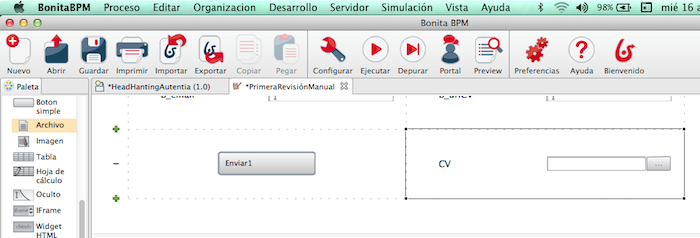
En los formularios podemos añadir
campos adicionales. Vamos a añadir un documento adjunto.
Parece lógico que en
un proceso para gestionar el CV aparezca un campo para adjuntar el cv en
formato pdf. Arrastramos de la barra lateral un elemento de tipo archivo.
Y creamos un elemento nuevo de
tipo documento para asociárselo.
Durante el flujo podríamos almacenar el
documento en un gestor documental.
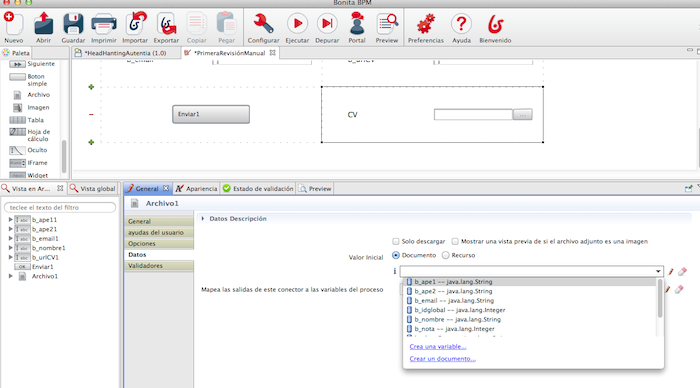
Ya tenemos el documento asociado
y vemos su comportamiento.
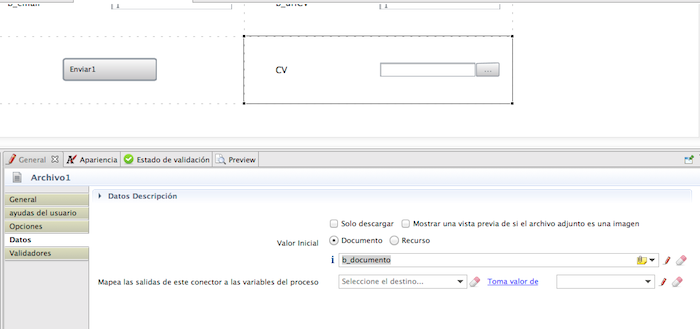
Vamos a hacer antes un retoque
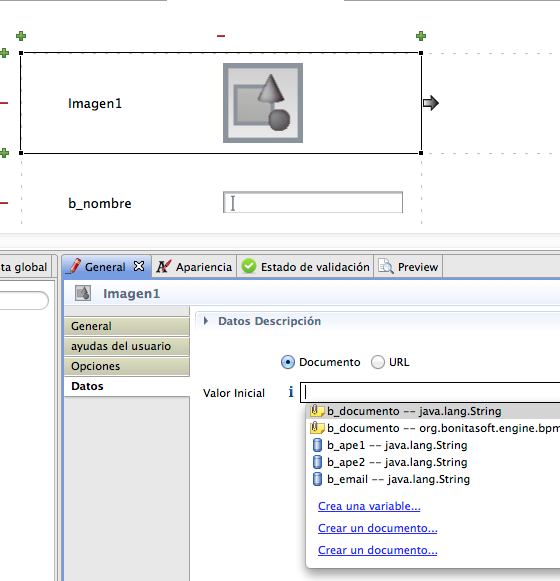
estético a ver como queda. Podemos añadir imágenes.
El documento puede ser interno
cargado desde un fichero.
Insertamos un logo.
En cada tarea lo lógico es que cada usuario solo vea los campos que
necesita ver. Por ejemplo, si un técnico hace la entrevista técnica e informa
al sistema, puede no ser conveniente que vea el salario que solicita. Igual
puede pasar que el evaluador no técnico no debería ver la evaluación de técnico
porque le puede condicionar.
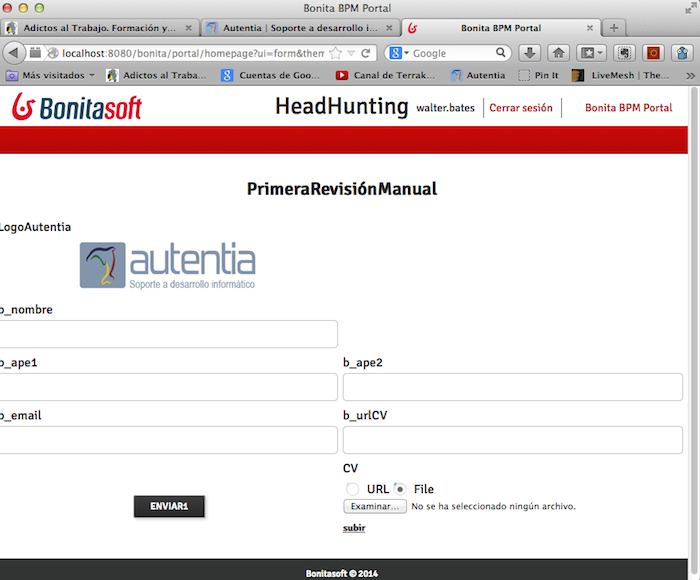
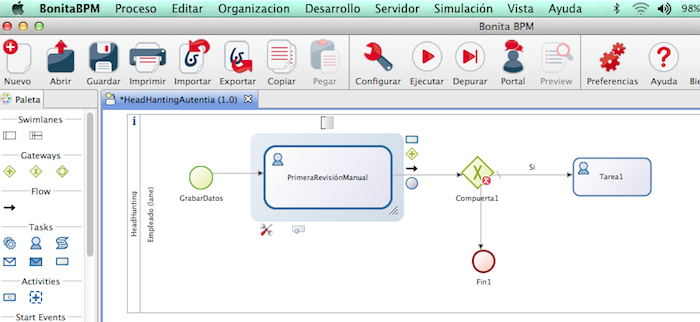
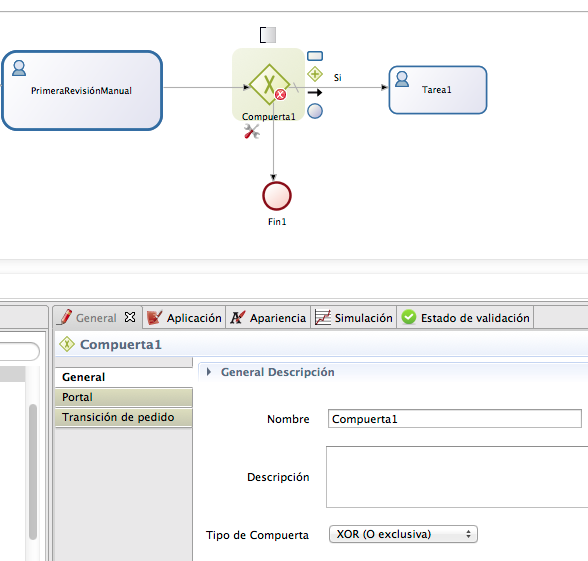
Normalmente el proceso, en base a
un cálculo o algún campo informado se hacen bifurcaciones. Pinchando y
arrastrando aparece el símbolo. La X representa que es o un trayecto u otro
XOR.
Debemos definir una condición en cada trayecto. En uno de ellos, si lo
marcamos por defecto, aparecerá una raya.
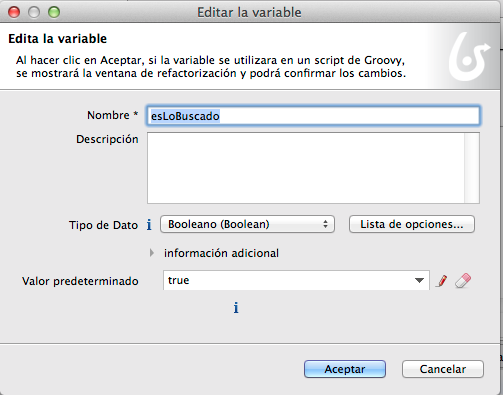
Normalmente tendremos que crear
(como en cualquier programa) variables de flujo globales que se arrastren entre
distintas tareas.
Vemos como se marca un trayecto
por defecto.
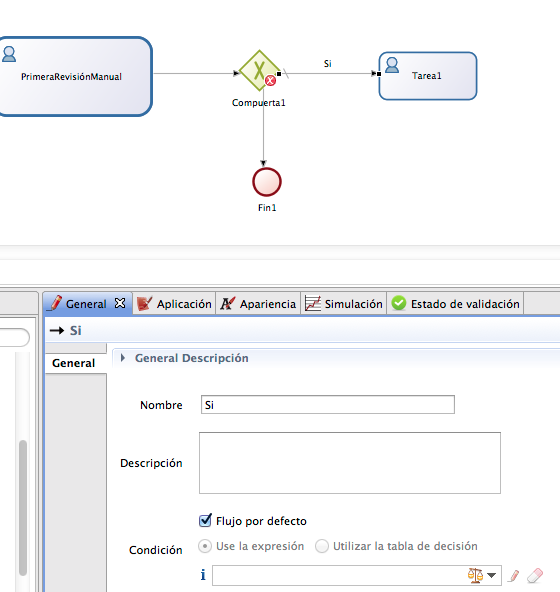
El motor utiliza scripts de
Groovy. Las comparaciones, como en Java, se hacen con ==
Si queremos que el campo sea
rellenado por el entrevistador en el primer filtro de CVs deberemos añadirlo al
formulario y mapear los datos.
Adicionalmente a guardarse los
datos en el flujo vamos a grabarlos en una base de datos (aunque ya hemos dicho
que esto es cómodo pero no siempre la mejor opción). Para hacerlo debemos ir a
la sección conectores.
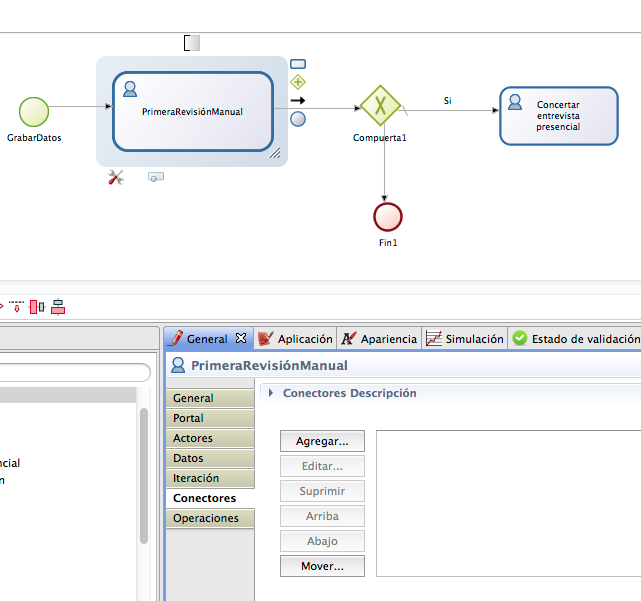
Elegimos PostgreSQL.
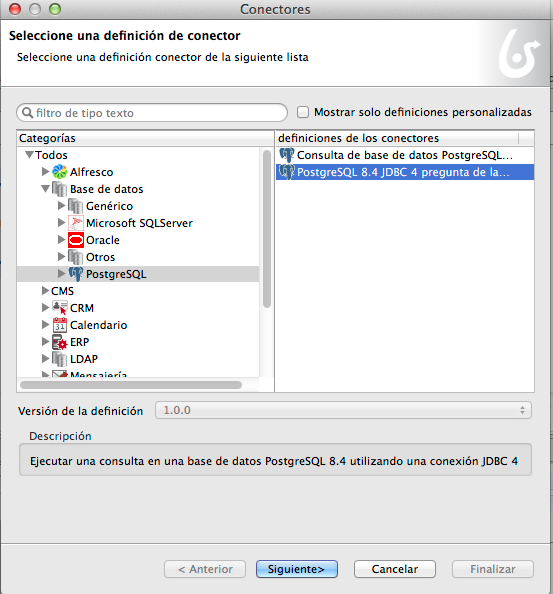
La acciones podemos definir que
se haga al entrar o al finalizar la acción.
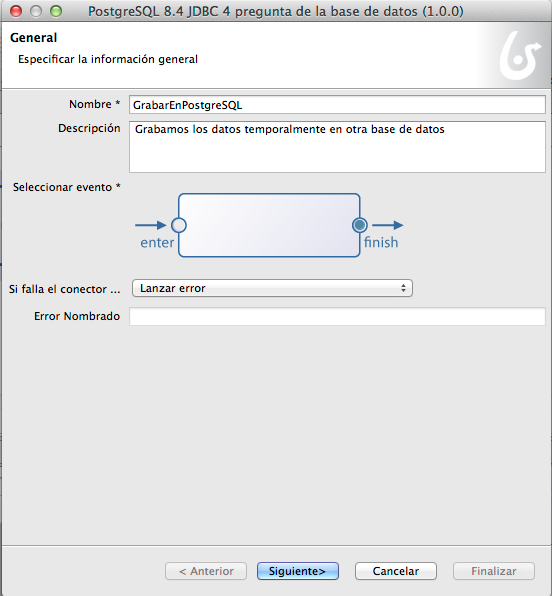
Elegimos el driver de la base de
datos.
Establecemos la cadena de
conexión y contraseña.
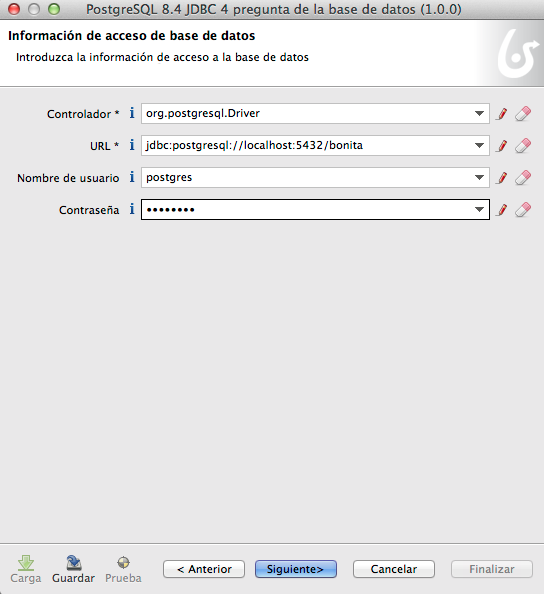
Estas pantallas ya son de la
herramienta de administración de la base de datos. Vemos el esquema de los
campos.
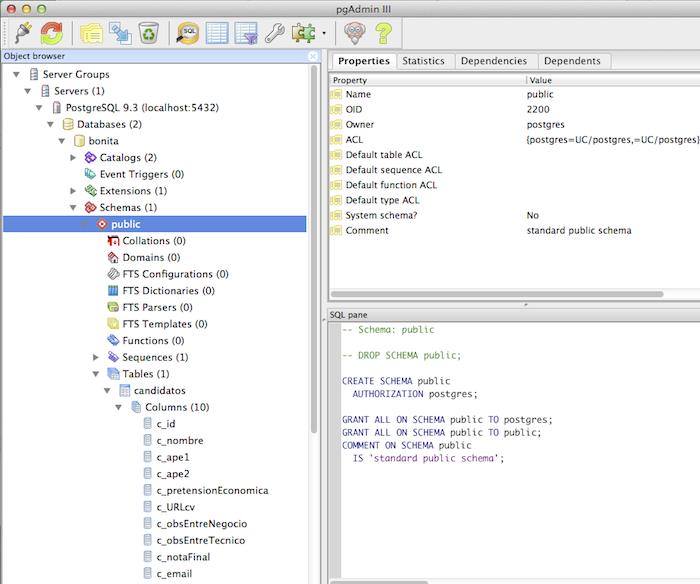
Si pulsamos en el script insert
nos saca una muestra del sql necesario.
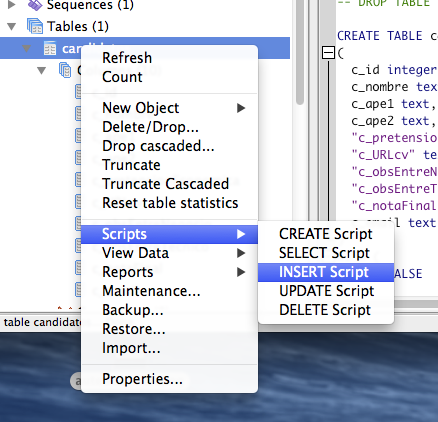
Solamente tendremos que sustituir
las interrogaciones por los campos. Eso se hacer con ${nombre_campo}.
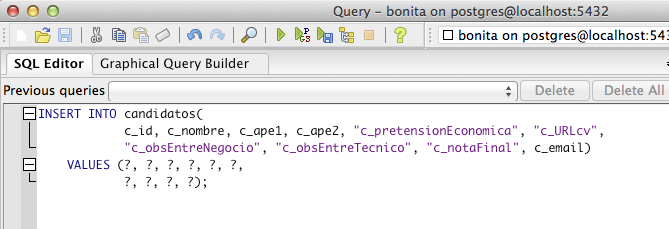
El resultado lo introducimos en
el Script dentro de Bonita.
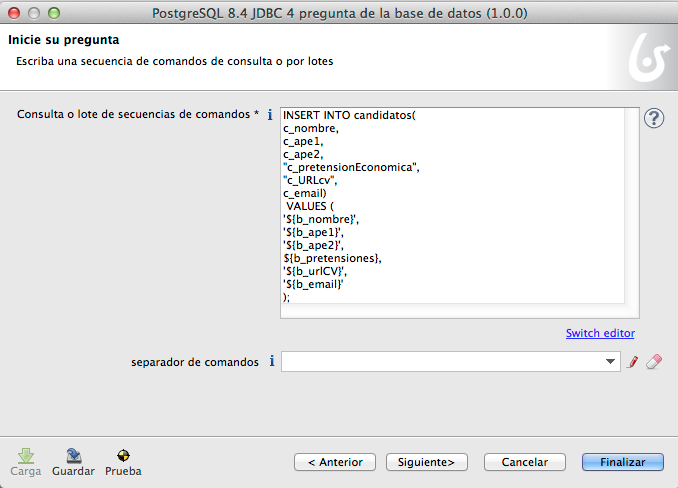
Queda tal que así:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
INSERT INTO candidatos(
c_nombre,
c_ape1,
c_ape2,
"c_pretensionEconomica",
"c_URLcv",
c_email)
VALUES (
'${b_nombre}',
'${b_ape1}',
'${b_ape2}',
${b_pretensiones},
'${b_urlCV}',
'${b_email}'
);
|
Ahora arrancando el proceso solo
tenemos que comprobar en la base de datos que se están insertando los
registros.
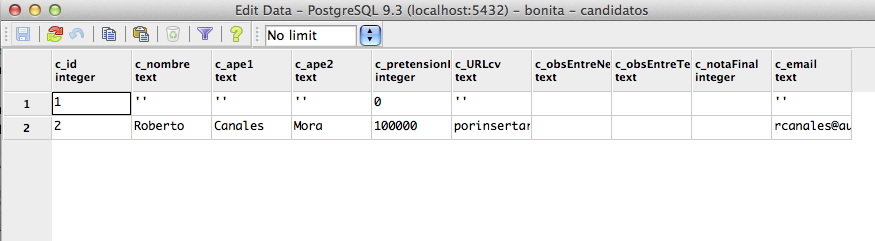
Lógicamente esto es un primer
paso. Si creamos el resto de formularios y roles en la organización, habremos
creado una aplicación básica orquestada dentro de un portal Web.
Editado
Lechiguero
información extraída de adictosaltrabajo.com
No hay comentarios:
Publicar un comentario